Topic model of fully-transcribed correspondence in Letters 1916-1923
This topic model was created in 2020 (based on data exported in December 2019) to track the evolution of the collection since the 2016 topic model created by Roman Bleier. Back then, 15 topics were identified that largely corresponded with the manual tagging system used by the *Letters 1916* team.
 As the collection expanded to cover not only the Easter Rising but also the end of the First World War, the Irish independence and the Irish Civil War, a revision of tags was necessary. As volunteers adding letters as well as users searching for letters in the front-end should not be overwhelmed, we nevertheless needed to limit the overall number of categories. The 2020 topic modelling helped us check the validity of the newly-assigned content tagging.
As the collection expanded to cover not only the Easter Rising but also the end of the First World War, the Irish independence and the Irish Civil War, a revision of tags was necessary. As volunteers adding letters as well as users searching for letters in the front-end should not be overwhelmed, we nevertheless needed to limit the overall number of categories. The 2020 topic modelling helped us check the validity of the newly-assigned content tagging.
Using the Python package SciKit learn, which combines LDA topic modelling with NMF, we identified 18 topics for our 3049 fully-transcribed letters as the most meaningful description of the extended collection. The script to generate this topic model was adapted from a tutorial by Allen Riddel and improved following discussions with the Sicit Learn development team. A custom stop word list in English, French and German including frequent Irish postal expressions such as "sráid" ("street") was imported via the NTLK package. The major challenge in the Letters 1916-1923 collection is not that many synonyms occur, but that many words, especially adjectives and adverbs, are found in very different contexts that are not easily captured by lexical disambiguations. Letters, postcards and telegraphs are comparatively short texts containing multiple conventional phrases. Names of (famous) people and places (such as POW camps) as well as specific salutations can thus provide a lot of necessary context and were not excluded. Data issues such as broken XML tags and faulty UTF-8 encoding in the original files, however, required careful pre-processing of the transcriptions. The stop word list had to be amended several times. This is why semi-manual evaluation of the topic model was vital to gain interpretable results. An initial topic model of 15 topics retrieved three topics that were too broad ("law, business", "administration, public welfare, social issues", "mobility, movement"), whereas a topic model of 20 topics contained two topics on family affairs that were nearly identical. Due to the overall limited vocabulary of the collection, topic models with a higher ratio of unique words did not generate more valuable topics. In the final 18 topics, only 50% of the top 25 words per topic do not rank equally high in any other topic.
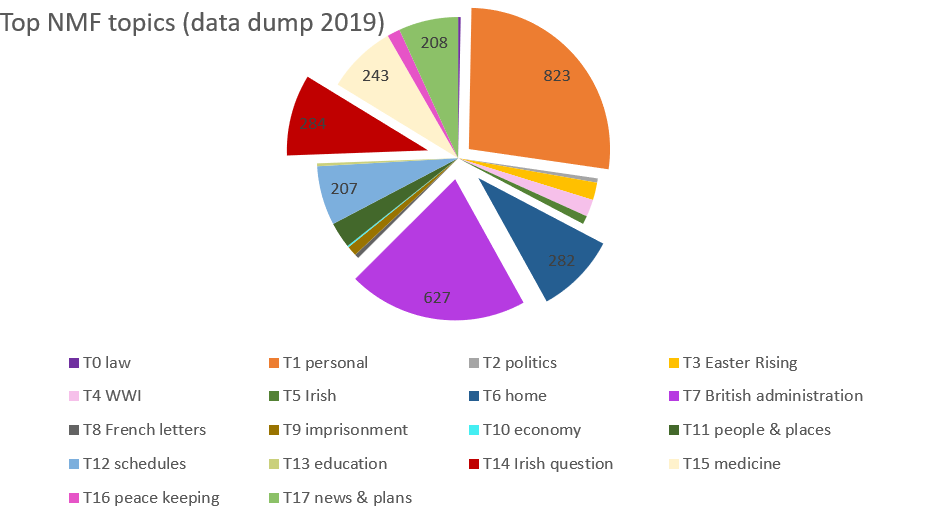
The linked table shows the 18 topics identified as the most meaningful and our interpretations.
Analysing the relevance of these topics across the 3049 transcriptions, we find that "personal relations" is the most dominant topic overall. This matches the analysis of our manually attributed categories. At the same time, the automated topics give a more nuanced insight into the different aspects of government proceedings and administration covered in our letters. Also, it is interesting that "imprisonment" forms a topic of its own as the Letters 1916-1923 database contains many prison letters from the First World War as well as the Easter Rising and the Irish Civil War. The topics concerning correspondence in Irish and French show that the collection has become more diverse in terms of language as well as content. French (and German) letters in the collection are intervowen with the First World War (e.g. the aristocratic Ballindoolin collection), whereas Irish letters predominantly come from Irish-Republican circles between 1918 and 1923. Possibilities for more advanced topic modelling in the future may be to exclude particularly ambivalent expressions and to work with translations of foreign words.
Please check the data table for details. For insights into the challenges of working with multilingual corpora or corpora that contain outdated forms of English, consult issue #17929 in the Scikit Learn issue tracker.