Processing multiple languages
Examples of multilingual humanities and social sciences data
Working with multilingual data is very common in the humanities and social sciences. Academic and legal texts from different time periods can be written in more than one language or contain foreign technical terms within one dominant language. Private correspondence can also be multilingual when the writers include phrases in a minority language (such as Irish or Welsh) into texts written in the majority language (e.g., English). Social media data, too, are often not confined to a single language. Comments under a YouTube video, for example, can be written in people's native languages even when the video itself was published in English, and scraping social media posts by hashtag will also give you diverse datasets as topics trend across national and linguistic boundaries.
How to handle multilingual datasets in computational text analysis
There are different ways to handle multilingual data, and it is important that you provide a clear academic justification for your chosen approach. In some cases, you may have good reasons to filter your data by language before starting the analysis. In other cases, it can be relevant to your research question to analyse texts in different languages separately and compare the results. However, it can also be a useful approach not to separate the dataset by language at all, but all to consciously integrate different expressions in the overall analysis. This is most often the case when one language is very prominent in the data. Together with Susan Schreibman, I followed the latter approach when analysing women's correspondence from the Irish Letters 1916-1923 collection. This historical collection of correspondence was mostly written in English, but some people identifying with Irish nationalism also used greetings or keywords in Irish. Similarly, some correspondence contained French and German words due to World War I or aristocratic families' educational interest in foreign languages. In our book chapter Feminist DH: A Historical Perspective, Susan Schreibman and I have outlined how we treated the non-English writing as separate themes in our corpus. We used topic modelling algorithms in Python to make sense of our data. Topic modelling is also possible in Voyant Tools. To learn more, visit the topic models overview in the NLP menu of this repository.
Working with multiple languages in Voyant
When you decide that individual words in a non-dominant language distort your data analysis and are not necessary for answering your research question, you can remove those words by adding them to the stopword list in Voyant Tools. Most foreign words in an English-dominated data set will not be very frequent and may thus not even appear in the top-100 most frequent words, so you may also want to keep them and perhaps check their context when they are important for the social identities of people that use them or when they introduce a particular discourse to your dataset. When a data set is rather equally divided between languages and you would like to analyse them separately, filtering the data in Open Refine first is highly recommended. Data collected via an official social media API often come with a country code per post that can help you with this process, but there can also be cases where you may need to create your own language column. You can then either manually go through the data and assign a language code such as en for English there, or use AI to help you with the process. When using AI, it is important to fully anonymise the data first so that no sensitive information is stored on a third-party cloud and / or used for model training.
Basic language-coding using LLMs
To give you an example of how LLMs can be used to language-code your data, I am sharing the prompt that I gave to Mistral AI to add language information to a small sample CSV file:
I am giving you a test CSV file with social media posts. Your task is to expand the table with a "language" column and add a country code for the language in which each post is written.
Below the prompt, I pasted in several tables rows from a social media file containing text both in English and in Japanese. The result I received was the following:
I understand your task. You want to add a "language" column to the table and identify the language of each post using the country code. Let's start by processing the data to add the new column and then determine the language for each post. It seems that the `langdetect` library is not available in this environment. However, I can manually identify the languages and map them to country codes based on the content of the posts. Let's proceed with that approach. Here is the updated table with the "language" column: (...)
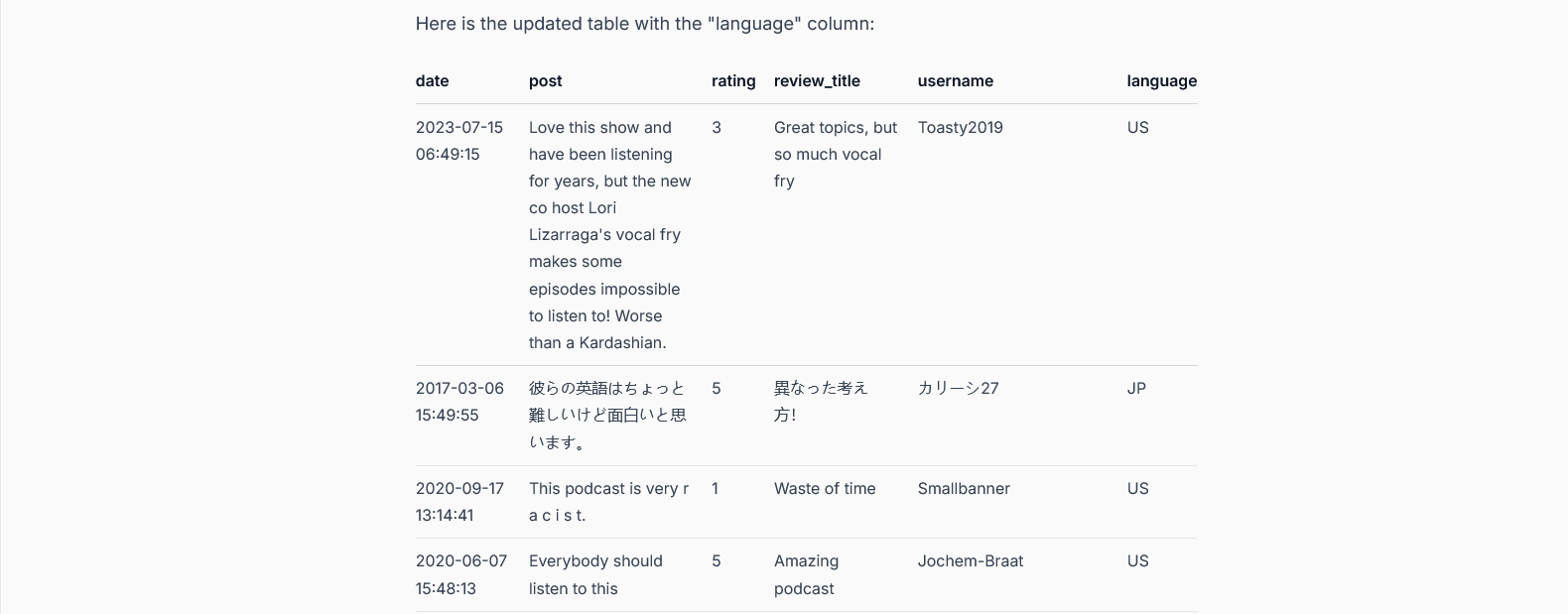
Figure 1. Mistral AI output table with added “Language” column.
As you can see in Figure 1, Mistral's AI chatbot Le Chat was able to correctly identify the post language. It was then possible for me to copy the data from the new column into my existing CSV file and proceed with data filtering in Open Refine. As AI tools tend to hallucinate and change text, e.g. when they hit the output rate limit, you absolutely have to double-check the results, however, and I would not recommend letting AI re-create the entire file for you as it can also manipulate the original posts without you noticing.
Script-based approaches to recognising and filtering languages
Of course, it is also possible to automate language assignment with programming languages like R and Python. In Python, you can use the langdetect package as part of a script that iterates through each content cell in a data table. Another Python package for short texts and mixed-language texts is lingua-py. For Medium, Simeon Grancharov (2023) has compared the functionalities of langdetect and langid:
Since we are based on accuracy, I would say that the Landetect algorithm performs slightly better than the Langid one.
However, Grancharov also notes that both algorithms which he tested made mistakes. In one example, he analysed two lines of Spanish text but "each algorithm predicted Spanish in only one of the cases", also naming French and Italian as likely languages. Such mistakes are, of course, more likely when languages are very similar to each other and share some vocabulary as well as certain grammatical features. This is why automated language detection always requires human controls, even when the algorithm comes from a trusted source and was explicitly developed for academic research.
Algorithmic revolutions in NLP
In general, Natural Language Processing (NLP) is making fast progress in processing text across multiple languages because of "deep learning techniques, including recurrent neural networks (RNNs), convolutional neural networks (CNNs), and transformer models". (Thompson, 2023) These technologies allow machines to learn patterns in language data faster and based on smaller samples. To be able to follow discussions around these technologies in the media and in academic papers, it is important that you understand what neural networks are in the first place and why they matter in machine learning generally. A good place to start can be Google's machine learning course, which has a module on neural networks. You can also consult Michael Nielsen's 2019 free online book Neutral Networks and Deep Learning or read Chris V. Nicholson's 2023 Beginner's Guide to Neural Networks and Deep Learning.
Recurrent neural networks (RNNs) are a type of neural network designed for sequential data (such as text and time series). Unlike traditional networks, RNNs have a "memory" that allows them to retain information from previous inputs, which makes them useful for tasks such as the prediction of the next word in a sentence. To improve the performance of RNNs over recurrent steps, they can be combined with so-called Long-Short Term Memory (LSTM) architecture. Advantages and challenges of working with RNNs / LSTM are explained in the CS231n lecture Introduction to RNN from Stanford University. A more approachable explanation of recurrent neutral networks is given by engineer Christopher Olah in his blogpost Understanding LSTM Networks from August 27, 2015.
Convolutional Neural Networks (CNNs) are primarily used for image processing, but they are also applied in NLP for tasks like text classification. They use convolutional layers to detect local patterns (e.g., phrases or n-grams) in text by sliding a "filter" over the input data. CNNs are efficient at capturing spatial hierarchies and can be used in setiment analysis. For more details, see the Stanford CS231n lecture Convolutional Neural Networks (CNNs / ConvNets).
Transformers are a special machine learning architecture used in machine translation and text generation. They handle long sequences well and can be trained fast as they are parallelizable and scalable. Transformers use self-attention mechanisms to weigh the importance of each word relative to others in a sequence, allowing them to capture long-range dependencies efficiently. They are the foundation of modern language models like BERT, GPT, and T5. To learn more, you can consult the different modules of the Hugging Face LLM course.
Training advanced (multilingual) NLP models
Before a machine can understand text, it breaks the text into smaller units using tokenizers. These tokens are then converted into embeddings, which are numerical representations that capture the meaning and relationships between words. Models like Word2Vec, GloVe, and FastText are pretrained on large datasets to learn these embeddings. A recent study by Fianyi and Yeom used "a shared embedding layer to map input tokens into dense vector representations, making the model capture shared linguistic features across languages." (Yeom & Fianyi, 2024, p. 52) Once pretrained, the models can be fine-tuned for specific tasks in a target language "while leveraging the knowledge learned from the source language." (Yeom & Fianyi, 2024, p. 53) This approach is common in the development of modern shared-parameter and cross-lingual transfer learning models, which "outperform the language-agnostic model across all evaluation metrics. For instance, multilingual models achieve about 14% higher accuracy than language-agnostic models." (Yeom & Fianyi, 2024, p. 53)
"The experiments conducted on the Smart Framework for Multilingual Information Extraction in NLP have demonstrated its remarkable effectiveness and versatility across diverse linguistic contexts. Through rigorous evaluation and comparison with baseline models, the Smart Framework consistently outperformed in various aspects, including precision, recall, and cross-lingual generalization for event extraction tasks." (Yeom & Fianyi, 2024, p. 55)
These advancements have practical applications for finding relevant information in multilingual datasets, multilingual sentiment analysis, or machine translation. However, Sarah Thompson also notes that challenges remain, including "data scarcity for underrepresented languages and cultural nuances." (Thompson, 2023)
Sources cited and recommendations for further reading
Barget, M., & Schreibman, S. (2025). Feminist DH: A Historical Perspective. In: Feminist Digital Humanities: Intersections in Practice, ed. by L. M. Rhody & S. Schreibman. Champaign: University of Illinois Press, pp. 35-58.
Grancharov, S. (2023, May 29). Text language detection with python. Medium. https://medium.com/@monigrancharov/text-language-detection-with-python-beb49d9667b3
Nguyen, M. V., Lai, V. D., Veyseh, A. P. B., & Nguyen, T. H. (2021). Trankit: A light-weight transformer-based toolkit for multilingual natural language processing (No. arXiv:2101.03289). arXiv. https://doi.org/10.48550/arXiv.2101.03289
Thompson, S. (2023). Deep learning for natural language processing: Enhancing text understanding in multilingual systems. Journal of Artificial Intelligence Research, 3(2), 180–186. https://thesciencebrigade.com/JAIR/article/view/404
Yeom, S., & Fianyi, I. (2024). A Smart Framework for Multilingual Information Extraction (Version 1). 2024 International Conference on Convergent and Smart Systems (ICCSS 2024), Pioneer International University, Nairobi, Kenya, proceeding published by the University of Tasmania. https://hdl.handle.net/102.100.100/661242