Topic modelling
Why topic models are used in computational text analysis
Topic modelling is an unsupervised machine learning technique used to discover abstract "topics" in a collection of documents. Topic modelling identifies patterns of word co-occurrence across texts while the number of desired "topics" created is defined by the user and strongly depends on the research question. Topic modelling helps researchers explore large text collections without reading every document and can also serve as a basis for more detailed manual coding (in qualitative research). However, topics generated by algorithms are statistical, not semantic. They represent clusters of words that often appear together, not human-like "themes" or "subjects." This distinction is crucial for your interpretation and explains the need to experiment with different topic numbers and iterations.
Statistical versus semantic topic identification
The reason why a semantic topic identification cannot be performed with rule-based NLP algorithms but requires human intervention or the use of Large Language Models (LLMs) is that words have different meanings depending on context, and humans also use words ambiguously. The following three sentences are examples of text fragments that demonstrate this complexity:
- "Garden plants need a lot of water."
- "You have to boil water and cook the vegetables till tender."
- "Growing vegetables in your garden can be difficult when there are slugs."
A human reader will immediately recognize that the first and third texts focus on gardening, while the second text is about cooking. However, just looking at the vocabulary used, there are overlaps between all three texts:
- "vegetables" is used both in text 2 and text 3.
- "water" is used both in text 1 and text 2.
As a consequence, a statistical topic model like Latent Dirichlet Allocation (LDA) would to tokenize the sentences and count word co-occurrences, then group words that frequently appear together into "topics", but ingore context and treat words as independent entities. If you ask the model to identify two topics for you, you will receive output like this:
- Topic 1:
- Topic 2:
As a human reader, you would still likely interpret the first topic as cooking and the second as gardening, but the model per se cannot distinguish that "water" in the first sentence has a different usage than in the second sentence. The model also does not know that, in our sample, "slugs" are mentioned as a garden pest or that "tender" is related to food texture. This why it also never suggests a name or title for your topics other than topic 1, topic 2, etc. The labelling of topics always has to come from you.
When you give the same sentences to a Large Language Model (LLM), the model can, of course, make suggetions about context and meaning. Mistral.ai, for example, gives the following interpretation for the sample:
Sentence 1: "Garden plants need a lot of water." Topic: Gardening Reasoning: "Garden" and "plants" are strong indicators of gardening. "Water" is used in the context of plant care.
Sentence 2: "You have to boil water and cook the vegetables till tender." Topic: Cooking Reasoning: "Boil," "cook," and "tender" are strong indicators of cooking. "Water" is used in the context of boiling, and "vegetables" are being cooked.
Sentence 3: "Growing vegetables in your garden can be difficult when there are slugs." Topic: Gardening Reasoning: "Growing," "garden," and "slugs" are strong indicators of gardening. "Vegetables" are being grown, not cooked.
In some circumstances, it can be very useful that LLMs recognise semantic relationships, but the focus on word co-occurences is reproducible and avoids biases coming from training data or prompts. Also, the use of LLMs is energy-intensive and has a large environmental footprint. You should, therefore, carefully consider when and why the use of LLMs is necessary.
Topic modelling algorithms and their use cases
| Model | Description | Use Case Example |
|---|---|---|
| LDA | The most common model; assumes documents are mixtures of topics. | Exploring themes in historical newspapers. |
| BERTopic | Uses transformer models (like BERT) to create dense clusters for more coherent topics. | Analyzing social media posts. |
| NMF | Non-Negative Matrix Factorization; works well with shorter texts. | Studying customer reviews. |
| Top2Vec | Combines topic modelling with word embeddings for semantically richer topics. | Researching scientific literature. |
Note: No model is "perfect." The choice depends on your data and goals. Always validate your topics by reading sample documents from your corpus.
Tool 1: Topic modelling in Voyant Tools
Voyant Tools as web-based platform for text analysis also includes a topic modelling option. In the interface of the Voyant suite, you can find it under Corpus Tools. This tool uses the Latent Dirichlet Allocation (LDA) algorithm, specifically the jsLDA implementation by David Mimno. The algorithm starts by temporarily assigning words in your documents to a set number of topics (you choose how many topics to create). This initial assignment isn’t meaningful yet — it’s just a starting point. The algorithm then goes through 50 iterations (or cycles) to improve the model. In each iteration, it adjusts which words belong to which topics based on how often they appear together in your documents. Over time, the topics become more coherent and meaningful. Because the process starts with a random temporary assignment, the final topics can vary slightly each time you run the analysis. This might seem inconsistent, but the topics usually maintain a logical structure. Think of it like shuffling a deck of cards: you’ll get a different order each time, but the same types of cards will still group together. In the topic output you see, only the top n (e.g. 10) words per topic are shown. The more words you include, the more overlaps you will see between the topics you created as each topic actually includes all word in your topic in the end. However, the words are ranked by how strongly they relate to the topic, with the first few words being the most defining for that topic.
To better understand what is happening behind the tool, you can use the Spyral Topic Modelling Notebook by Geoffrey Rockwell that walks you through the actual code. You don’t need to write any code from scratch but can read the explanations and follow the notebook’s steps. Like the user interface in Voyant, the topics notebook starts by loading a text corpus (e.g., the default "Frankenstein" text). The notebook then runs a probabilistic model (LDA) to identify topics and displays the results in a panel. You can adjust the number of topics and words per topic to fit your needs. This notebook is shared under a Creative Commons Attribution (CC BY) license and you may adapt it for your own projects.
Tool 2: DARIAH-DE Topic Explorer
The DARIAH-DE Topic Explorer is another beginner-friendly tool for topic modelling and specially designed for humanities research. It also uses LDA to generate topics from your text collection. Similar to the Voyant topic modelling, the Topic Explorer allows you to upload plain text files (one per document), set stopwords and parameters, and run the model repeatedly. No coding skills are required. It is recommended to start with a small number of topics (5 to 10) and increase gradually. It is rare that you will already get the best result in the first attempt.
One unique feature of the DARIAH Topics Explorer going beyond the Voyant functionalities is that you can also display topic-document proportions as a heat map (see Figure 1). This heat map provides a clear, color-coded overview of how strongly each topic is represented across all documents in your corpus. It helps you quickly identify which documents are most relevant to specific themes.
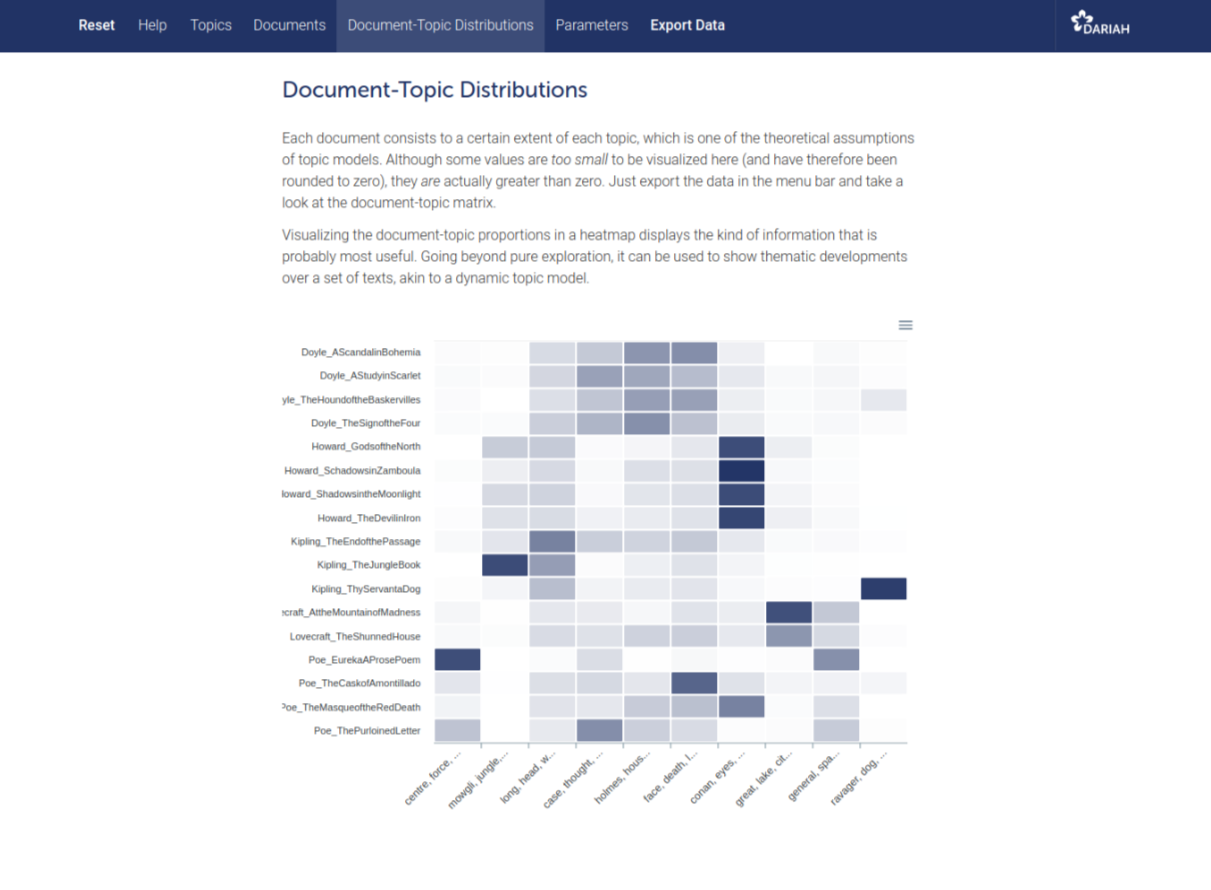
Figure 1: Heat map of topic–document proportions generated by the DARIAH Topics Explorer.